Published
- 1 min read
LLaVA
LLaVA
地址
点击查看 👆 click 👋
简介
LLaVA(Large Language and Vision Assistant)是一个由威斯康星大学麦迪逊分校、微软研究院和哥伦比亚大学研究者共同发布的多模态大模型。该模型展示出了一些接近多模态 GPT-4 的图文理解能力:相对于 GPT-4 获得了 85.1% 的相对得分。当在科学问答(Science QA)上进行微调时,LLaVA 和 GPT-4 的协同作用实现了 92.53%准确率的新 SoTA。
特点
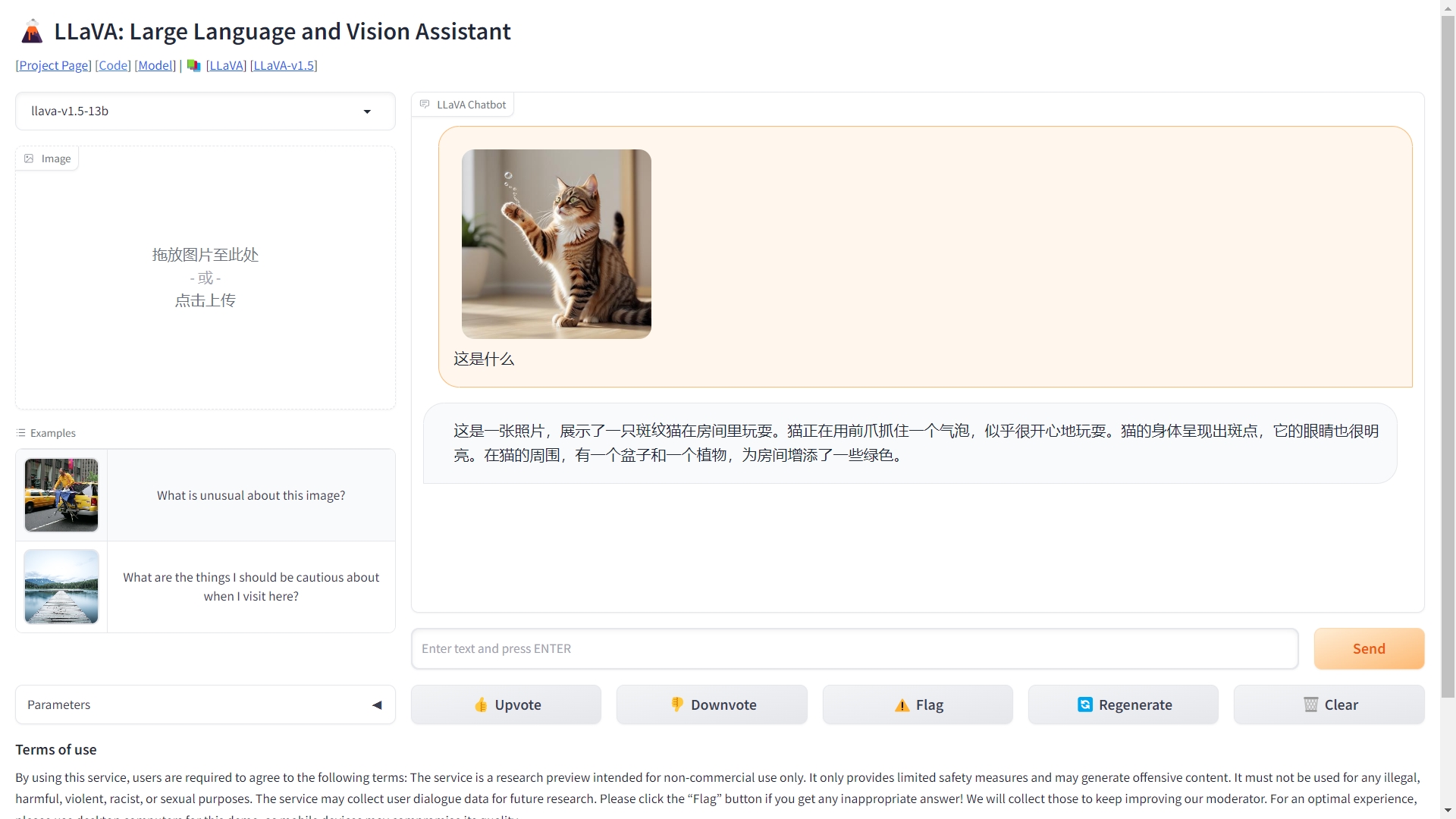
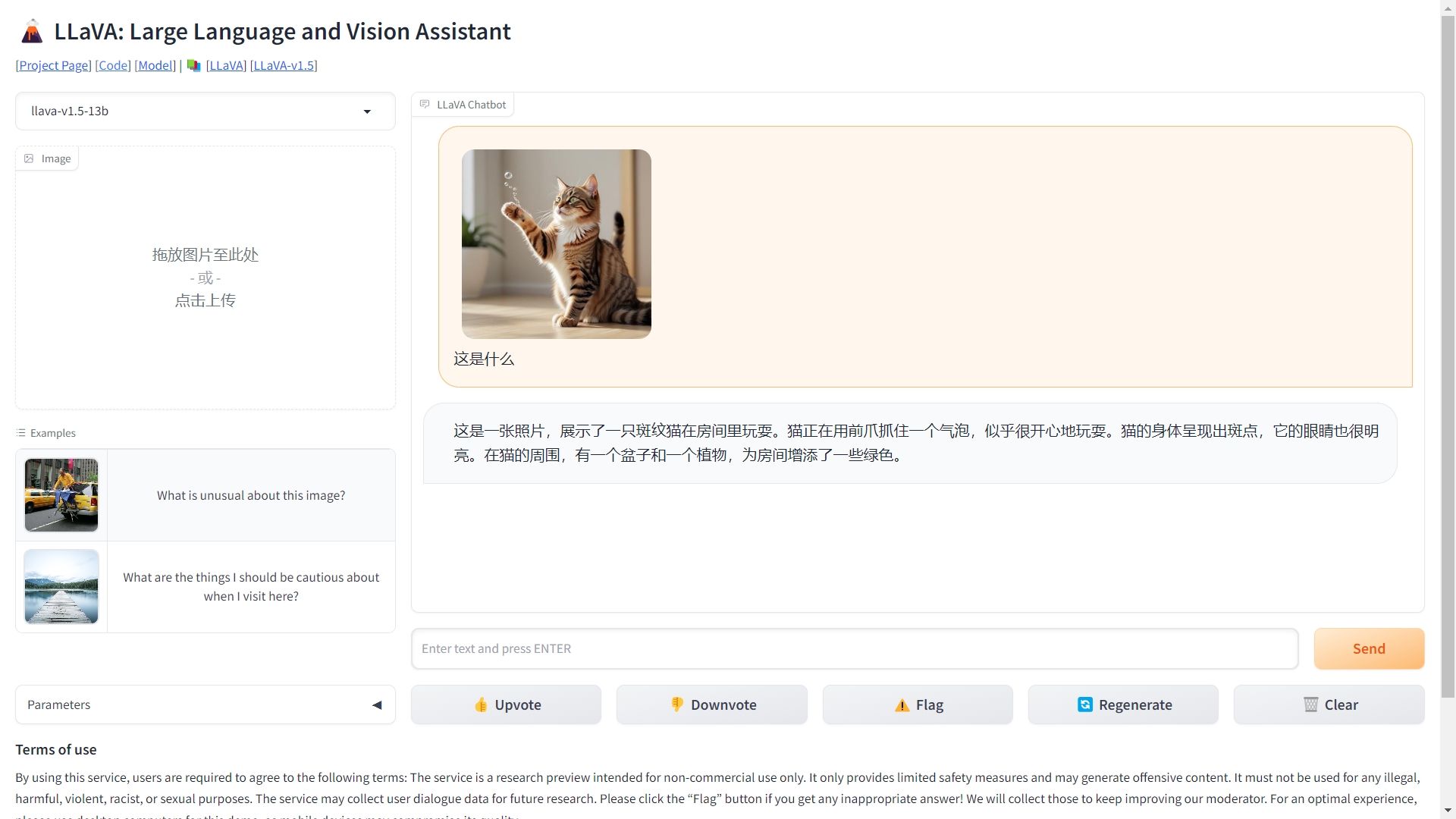
- 免费的图片识别能力
- 支持调整参数
截图